Understanding and updating MIGO defaults in ABAP
Posted: July 29, 2014 Filed under: SAP, SAP ABAP Leave a commentPosted on SCN at http://scn.sap.com/community/abap/blog/2014/07/28/understanding-and-modifying-migos-defaults-programmatically.
Recently I had a situation where I needed to update MIGOs defaults programatically. I tried to search for a solution but couldn’t see it mentioned anywhere and hence decided to write it down . I hope that it’ll be useful for anyone in a similar situation.
Background:
MIGO is a multi-purpose transaction which can be used for various activities in material management – performing goods movements, receipt of purchase order etc. It replaces many older transactions . There are others as well but to list down a few:
- Post a goods receipt to a known purchase order (transaction MB01)
- Change a material document from goods receipts (transaction MB02)
- Display a material document from goods receipts (transaction MB03)
- Cancel a material document from goods receipts (transaction MBST)
To understand why we may need to ever need to modify MIGO defaults, consider the below situation.
– A file arrives for processing in SAP ( say as a batch job ) .
– Initial goods movement is tried using a BAPI. If the processing fails , a user SM35 BDC session is created for processing which can be reprocessed by users ( the users are familiar with MIGO ). A custom transaction for reprocessing is created as the users couldn’t be given access to SM35. SM35 allows you to display and potentially reprocess all sessions which can be tricky if the authorisations are a bit leaky.

The failed sessions can then be processed by a custom transaction – the SM35 sessions are persisted to a temporary table to be used by reprocessing transaction.
Problem:
Everything looks good in theory : all automatic postings are done in background and any errors can be handled by the custom transaction. However, while the user is performing the reprocessing the MIGO session, something interesting happens – if the user opens a parallel MIGO session and performs some other processing in parallel, the subsequent sessions start to fail in the custom transaction. Users could be processing multiple sessions sequentially and might go away and do some other movements in parallel in MIGO.

Why does this happen ?
MIGO stores user’s defaults trying to optimise the usage so that the user doesn’t have to set the selections – this causes the defaults to be always set whenever you use the transaction. The parallel session which the user opened has overridden the defaults and as a result, subsequent failed sessions have different default values set in the screen even though the BDC recording used in SM35 session was set correctly. User defaults is overriding BDC set values .
Looking at the below image, the BDC session has set values A07 and R10 for action and sub-selection within action.

However, if the user choses something else in a parallel session ( say A05 and a sub-selection ) , it overrides the action default and subsequent SM35 sessions start failing as then MIGO will start with A05 / sub-selection.
Solution:
MIGO stores user’s defaults in table ESDUS and these defaults correspond to MIGO_FIRSTLINE action. Seeing the below table entries, the settings for the user are:
Default is action = A07
and sub-selection for A07 is R10.
Hence, A07 / R10 will appear for ACTION and sub-selection ( as shown in above image ) .

Show Me The Code:
Now, we know where they’re stored, how to update them ?
Class CL_MMIM_USERDEFAULTS can be used to read and update the parameters. It’s a singleton and hence there should be only instance at a given time. Consequently, if we’re using it we have to ensure the instance is destroyed . This is achieved by FLUSH_ALL method of the class. Above methods are self explanatory and the constructor requires ACTION value.

So I did the following:
– Instantiate the class using ACTION as “MIGO_FIRSTLINE” and set the instance values.
– Set the values:
o_migo_defaults->set
( i_element = ‘ACTION’
i_active = lv_action ).
– Flush the value to dB and destroy the instance
o_migo_defaults->flush( ). “Save values to dB
o_migo_defaults->flush_all( ). “Destroy this instance as others instance will start producing errors
The table has other values used in MIGO defaults ( e.g. default movement type for an action ) and can be similarly updated.
Integration Gateway in SAP Mobile Platform 3.0
Posted: July 6, 2014 Filed under: SAP, SAP Mobile Leave a comment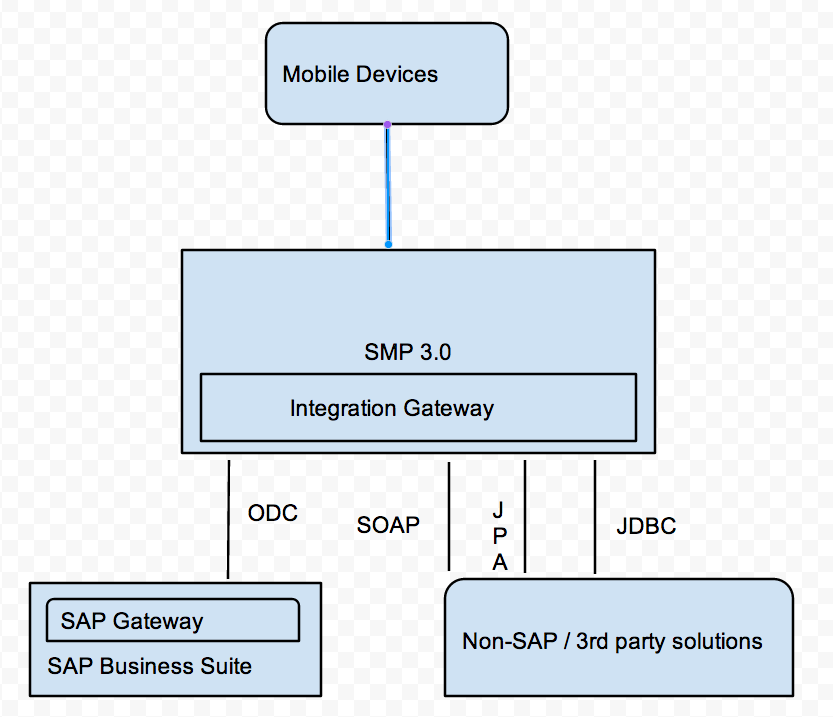
Main features of SMP 3.0 :
– SUP, Agentry and Mobiliser combined. This itself is a pretty big as each of the platforms had an integration framework and it had to be harmonised . It’s simplified to just use SMP with services exposed in oData format.
– Through SMP 3.0, services from ABAP backend ( using SAP Gateway ) and non SAP backends can be easily consumed. This is pretty powerful as data could be spread out over multiple kinds of data sources. It allows for data consumption from JPA, JDBC , SOAP etc.
– Eclipse GWPA has been enhanced for new features – to consume services from different backend types.
– A big drawback I see is that it doesn’t seem to talk about MBO based replication. My first iOS mobility project involved creating an iOS ( iPAD app ) using SUP which was based on MBOs and it’s sad to see them go. Support for offline capabilities is planned from later releases of SMP 3.0.
– A big positive is the ability to schedule different data based on speed ( or other requirements ) – the ability to assign priorities in scheduling is a big one – our users were extremely frustrated that they can’t control the information they wanted and had to wait for sync of everything from past before relevant data for today could be synced.
Comparisons between SAP Gateway and SAP Integration Gateway:
– ABAP based vs Lean Java server ( Java, OSGI ).
– Supports SAP vs Supports both SAP and non-SAP data sources.
– Available as a standalone solution vs embedded inside SMP 3.0 .
– On premse vs On premise / Cloud.
Youtube tip – change playback speed to 1.25x
Posted: July 6, 2014 Filed under: Learning Leave a commentOne hack I have been using a long time for educational videos on youtube.
Sometimes, the default speeds are not good enough – 1x is too slow and 1.5x is too fast . change it to 1.25x .
document.getElementsByTagName(“video”)[0].playbackRate = 1.25
SAP HANA CDS ( Core Data Services )
Posted: February 24, 2014 Filed under: HANA, SAP, SAP ABAP | Tags: ABAP, HANA, SAP Leave a commentWith SAP HANA platform, there has been a major shift in the way database is looked at. Traditionally, ABAP developers brought most of the data back to application server and manipulated based forming the core logic of the application.With HANA, the emphasis has been to do more in the databse ( akka code pushdown ).
However, there are some major drawbacks:
– It relies on development in two areas : HANA views / procedures which are then consumed in ABAP.
– Two separate mechanisms for ALM with ABAP and HANA transports.
With SAP NW 7.4 SP5, ABAP open SQL has been enhanced and views can be created using DDL. This is known as CDS ( Core Data Services ) .
Looking at an example: Create a basic view.
And the view can be consumed in ABAP – Need to add @ annotation .

These can be extended so that if DDIC additions are made, the view gets them automatically.

And the views can be made more complex.

and even more complex.

This to me looks like a step in the right direction as:
– it’s open SQL and hence is dB agnostic. Hence, it can be supported for other vendors databases in future.
– No separate development done in HANA reducing complexity of application development
ABAP SP5 on HANA is out
Posted: February 20, 2014 Filed under: HANA, SAP Leave a commentCloud Appliiance Library has been updated with SP5. This is a big release as it has lot of “code push down” features.
Performance Worklist Tool: The SQL Performance Worklist (Transaction: SWLT) allows you to correlate SQL runtime data with ABAP code analysis to plan optimizations using results from the new SQLMonitor and CodeInspector.
CDS Viewbuilding: CDS Viewbuilding is drastically improving the existing viewbuilding mechanisms in ABAP.
Extended OpenSQL: Open SQL has been enhanced with new features, especially a lot of limitations have been removed, the JOIN functionality has been enhances as have been arithmetical and string expressions.
ABAP managed Database Procedures (AMDP): AMDPs enables you to create database procedures directly in ABAP using e.g. SQL Script and to seamlessly integrate it in modern ABAP development. An AMDP can be implemented using an ABAP method.
And then there are additions to ABAP.
– MOVE-CORRESPONDING for Internal Tables : No longer RTTI required for such activities.
and some more:
Expressions and Functions
Table Comprehensions
Meshes
Open SQL additions
Links :
http://help.sap.com/abapdocu_740/en/index.htm?file=ABENNEWS-740_SP05.htm
http://help.sap.com/abapdocu_740/en/index.htm?file=ABENABAP_HANA.htm
Two more enhancements with the solution from CAL ( Cloud Appliance Library ) :
– Front End provided , installation of eclipse and HANA studio no longer mandatory e.g. if you have a mac.
– BW is present in the same system.
SAP ABAP HANA AWS Issues
Posted: February 11, 2014 Filed under: HANA, SAP Leave a commentMany a times the HANA instance doesn’t work even though CAL shows green status. We can try just restarting or use the below steps.
- Connect to the instance via putty
- On the command prompt please execute cat /etc/hosts
and check if the ip address of the instance is correctly mapped to the hostname - Switch user via command: su – a4hadm
- Execute the commands:
ABAP status: sapcontrol -nr 00 -function GetProcessList
HANA status: sapcontrol -nr 02 -function GetProcessList - If everything is green you have a connectivity problem this means SAP GUI can’t connect via
your VPN connection to the instance. - If either of the services shows gray or not green, you have to option to restart the complete
instance via the CAL console or you refer to the description in paragraph 8.2
of the document http://scn.sap.com/docs/DOC-45725
which describes how you manually start and stop the services.
SAP ABAP HANA Additions
Posted: February 11, 2014 Filed under: HANA, SAP Leave a commentHANA SQLScript Reference :
Click to access SAP_HANA_SQL_Script_Reference_en.pdf
SHINE Ref :
Click to access SAP_HANA_Interactive_Education_SHINE_en.pdf
Code push down has been the key with HANA but with AMDP ( ABAP Managed Database Procedures ) and CDS ( Core Data Services ), the extra effort of creating objects in HANA as well as ABAP doesn’t need to be done anymore.
AMDP :ABAP Managed Database Procedures are a new feature in AS ABAP allowing developers to write database procedures directly in ABAP. You can think of a Database Procedure as a function stored and executed in the database. The implementation language varies from one database system to another. In SAP HANA it is SQL Script. Using AMDP allows developers to create and execute those database procedures in the ABAP environment using ABAP methods and ABAP data types.AMDPs are introduced to easily enable you to get the best out of ABAP for HANA following the “code push-down” paradigm first introduced with SAP NetWeaver AS ABAP 7.4 .
Creating an AMDP is as easy as it can get in ABAP. You can simply implement SQLScript in an ABAP method:
METHOD <meth> BY DATABASE PROCEDURE
FOR <db>
LANGUAGE <db_lang>
[OPTIONS <db_options>]
[USING <db_entities>].
< Insert SQLScript code here >
ENDMETHOD.
– Every class with AMDP must use interface IF_AMDP_MARKER_HDB.
AMDPs are visible through SE80 but can’t be edited from there.
ABAP Object Services: Some useful additions
Posted: February 9, 2014 Filed under: HANA, SAP, SAP ABAP | Tags: HANA, SAP, SAP ABAP Leave a commentFrom my SCN blog : http://scn.sap.com/community/abap/blog/2014/02/09/abap-object-services-some-useful-additions-to-persistent-and-transient-objects
All modern programming language environments have some kind of ORM ( Object Relationship Mechanism ) mechanism. It allows persistence to be represented as programming language objects. In ABAP object services, we have persistent objects to hold data which we’ll save to database and transient objects to hold data in ABAP memory temporarily.
This blog summarizes my experiences in the additions I had to make while using object services in ABAP.
– In the points 1 and 2, I describe two features I wasn’t aware of but found them based on requirements.
– The last three examples under point 3 are enhanced methods I had to create using RTTI as they’re not created “out of box” by persistent generator mechanism – they’re not strictly persistence but I found myself wishing them with my persistent objects.
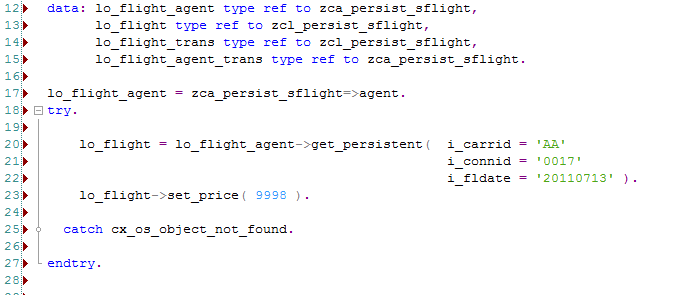
Just to recap about persistent objects, we can get a persistence reference and set values later. So in the below example, lo_flight is a persistent object and we can update price.
Below are the additions I had to make to get object services working efficiently in my own experience.
- Adding extra ( non-persistent ) fields to a persistent object : What if we need an attribute on the persistent objects not part of the underlying database table. These can be added as an attribute .

And then will show up as an attribute in the “Persistence Representant” view. As seen below, the attribute gets added .


The field gets added as a normal attribute to the class and can be removed (attributes coming from the table can’t be removed as they’re greyed out ).
As an example, I had to identify if a peristent object has been changed and I added an extra field ‘update’ for this purpose.
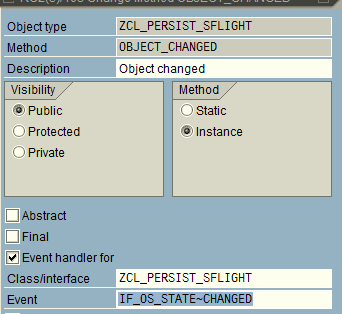
and then tie this attribute with the event IF_OS_STATE~CHANGED to indicate when the object has been modified.
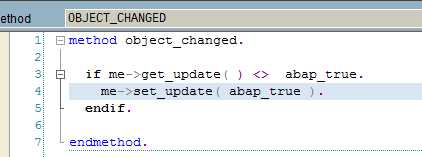
This can be handy if a transient object is converted into a persistent object . e.g. A screen’s PBO gets the transient object and the PAI can check if the object has been modified to trigger the conversion from a transient object to a persistent object.
2. Transient objects in place of ABAP memory: Using transient objects for structures to store memory within a session (as a replacement for ABAP Memory). Many a times, to transfer data with in a session, we export data into ABAP memory and then import it back again. This is fine but this can be difficult to debug in case the export / import locations are not well documented ( imagine data being exported to ABAP memory from an enhancement deep down in a stack and then trying to debug through to find why it’s not set).
A substitute can be to create transient objects from structures.
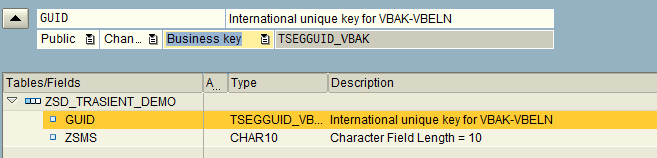
And we can create a business key which can hold distinct values.
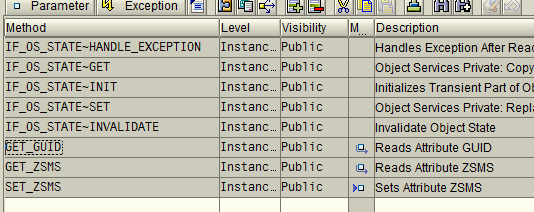
Looking at the method definitions.
We can create a transient object.

and then retrieve the values.
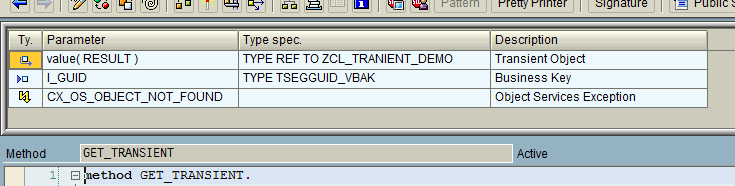
However, if the CREATE_TRANSIENT and GET_TRANSIENT are not in the same stack , this will fail . e.g. if the GET_TRANSIENT was called in a V1/V2 update process whereas the CREATE_TRANSIENT was in the main process, GET_TRANSIENT will fail.The below diagram represents it diagrammatically.

We still need to use SAP memory but at-least we can replace ABAP memory export / import calls by TRANSIENT objects.
3. Enhanced methods in persistence classes: The last three enhancements are based on addition of new methods to persistent classes. Like regular classes, methods can be added to them and are retained even with regeneration due to data dictionary modifications.
a) “Persist” transient objects: Converting transient objects into persistent objects: In point 1, if the object was modified, I was converting the transient object into a persistent one.
It is handy to be able to save a transient object into a persistent one. E.g. duing PBO of a screen, a transient object was created to read attributes and if attributes are modified, the save can be triggered by converting transient objects into persistent objects.
The below method can be called over the attributes we’re interested in persisting .
data: ls_method type seocmpname,
* ls_class type seoclsname,
lt_params type abap_parmbind_tab,
ls_param type abap_parmbind,
dref type ref to data,
lo_excep type ref to cx_sy_dyn_call_error, “#EC NEEDED
ls_par type abap_parmname.
field-symbols: <fs_attr_value> type any.
* To call the dynamic set_* methods, we need to populate kind, name and ref to actual value
* Create the dynamic method name : SET_<attribute>
concatenate ‘set_’ im_attr into ls_method.
translate ls_method to upper case. “#EC TRANSLANG
* Populate ref to data value
create data dref type (im_data_element).
assign dref->* to <fs_attr_value> .
<fs_attr_value> = im_attr_val .
ls_param-value = dref.
*We’re only setting values => param type is exporting
ls_param-kind = cl_abap_objectdescr=>exporting.
* Create the dynamic param name to be passed
concatenate ‘i_’ im_attr into ls_par.
translate ls_par to upper case.
ls_param-name = ls_par.
insert ls_param into table lt_params .
* Call the dynamic method
try.
call method me->(ls_method)
parameter-table
lt_params.
catch cx_sy_dyn_call_error into lo_excep.
raise exception type zcx_test_update
exporting textid = zcx_test_update=>dynamic_method_call_error .
endtry.
b) Convert persistent objects to structure : Sometimes we need to get the structure of persistent objects as there are some operations that can’t be done otherwise e.g. value comparison of all fields. It’s required to convert the peristent objects into structures.
DATA: lrf_structdescr TYPE REF TO cl_abap_structdescr,
lv_method_name TYPE seomtdname,
ls_component TYPE abap_compdescr.
FIELD-SYMBOLS: <fs_component> TYPE ANY.
* Request description of transferred structure
lrf_structdescr ?= cl_abap_typedescr=>describe_by_data( ch_struct ).
* Loop via all components of the transferred structure
LOOP AT lrf_structdescr->components INTO ls_component.
* Set the field symbol to the component of the transferred
* structure
ASSIGN COMPONENT ls_component-name OF STRUCTURE ch_surgery
TO <fs_component>.
* Compose the name of the GET method
CONCATENATE ‘GET_’ ls_component-name INTO lv_method_name.
* Determine the value of the attribute via a dynamic call of
* the GET method and write the value to the structure
TRY.
CALL METHOD me->(lv_method_name)
RECEIVING
result = <fs_component>.
CATCH cx_sy_dyn_call_illegal_method.
CONTINUE.
ENDTRY.
ENDLOOP.
c) Convert structures to persistent objects: And we sometimes need to convert the structure back to a persistent object.
RT_TEST is a reference to the persistence object.
DATA: lo_rtti_struc TYPE REF TO cl_abap_structdescr,
lt_field_list TYPE ddfields,
attr TYPE string,
attr1 TYPE string,
attr_val TYPE string.
FIELD-SYMBOLS: <fs_field> TYPE dfies,
<fs_attr_val> TYPE ANY,
<fs_attr_val1> TYPE ANY.
lo_rtti_struc ?= cl_abap_structdescr=>describe_by_name( struct_name ).
lt_field_list = lo_rtti_struc->get_ddic_field_list( ).
LOOP AT lt_field_list ASSIGNING <fs_field>.
CONCATENATE ‘me->’ <fs_field>-fieldname INTO attr .
TRANSLATE attr TO UPPER CASE.
ASSIGN (attr) TO <fs_attr_val>.
IF sy-subrc = 0.
attr_val = <fs_attr_val>.
attr = <fs_field>-fieldname.
CONCATENATE ‘RT_TEST-‘ <fs_field>-fieldname INTO attr1 .
ASSIGN (attr1) TO <fs_attr_val1>.
<fs_attr_val1> = attr_val.
ENDIF.
ENDLOOP.
SAP HANA with ABAP Installation
Posted: February 3, 2014 Filed under: SAP, Software | Tags: ABAP, HANA, SAP Leave a commentThese steps suffice for installation.
1. Order the appliance from SAP Cloud Appliance Library.
http://www.sap.com/pc/tech/cloud/software/appliance-library/index.html
2. Update AWS details and start the instance.
3. Download Hana Studio, SAPGUI and ABAP ( for Eclipse ) tools.
4. Install the IDEs – don’t install in Program Files. I had issues in getting the ABAP add-ons to show up . Installed in a separate folder and it worked fine.
5. Install licenses for HANA and SAP ABAP systems from SAP’s mini license site: https://websmp230.sap-ag.de/sap(bD1lbiZjPTAwMQ==)/bc/bsp/spn/minisap/minisap.htm
5. Takes around 40 minutes to start the first time around!
The system can be started / stopped from AWS as well but I’ve noticed that while starting the AWS console shows it’s working muche earlier. I prefer Cloud Appliance Library URL – https://caltdc.hana.ondemand.com/
Reference Links :
http://scn.sap.com/docs/DOC-44311
http://scn.sap.com/docs/DOC-41566
DEV GUIDE :
Click to access SAP_HANA_Interactive_Education_SHINE_en.pdf
Ref Scenario:
http://scn.sap.com/docs/DOC-35518
End to End Scenario :
http://scn.sap.com/docs/DOC-41437
Developer id : DEVELOPER with master password during installation.
SAP HANA : SAP Landing Page
http://www.saphana.com/community/learn/solutions/abap-for-hana
iOS memory management
Posted: February 2, 2014 Filed under: iOS/ ObjectiveC, Mobile Leave a comment– All objects have a property retaincount.
– copy, new, alloc and retain increase retain count by 1.
– release decreases retain count.
-autorelease decreases retaincount when the current run loop gets finished.
– Can create your own autorelease pools and drain them to reclaim memory.
Zones: Without zones small and large objects will be created together causing fragmentation. With zones, system creates two different zones – separate ones for different sizes of objects.
– Objects returned by Cocoa are normally autoreleased.
-in dealloc : [aProperty release]
or [self.property = nil]
bugs : app crash: something has been released or auto released and is being accessed
memory leak : memory was allocated but hasn’t been reclaimed even though not required
With ARC : Memory gets deallocated when all strong variables pointing to it are deallocated.
Strong, weak and unsafe_retained:
Strong : Valid till runtime and automatically released. Default for all local variables.
Weak : Zeroes ( sets to null ) the weak reference . So if a weak property points to a strong property and the strong property is released – the weak property is set to null.
unsafe_retained: Doesn’t get set to nil but set to a dangling location in memory.
While declaring them inline, use double underscore ..
__strong etc.
Why is weak needed: To avoid circular references.
[obj1 setObject:obj2]
[obj2 setObject:obj1]
Now both have circular references
