Installing SAP Trial ( NSP )
Posted: February 2, 2014 Filed under: SAP, SAP ABAP Leave a commentI’ve installed SAP ABAP trial at least a dozen times but keep forgetting some of the points and then end up wasting time trying to set up everything from scratch . I’ll summarize it for future reference as it’s really an easy process.
Software Requirements:
– Get the NSP trial version from SCN . Google it to get the latest version. Currently, the below URL has the link but who knows what’s the link in future. It should be in “SAP NetWeaver Main Releases’ section.
http://www.sdn.sap.com/irj/scn/nw-downloads
– Download SAPGUI installer separately. I tried using the one with the main bundle and it doesn’t work . SAP should just take it out to from the main package to remove any confusion.
– Install a JDK ( I installed JDK1.5, update 22 ) – not sure if a JRE will suffice but just to be sure I installed Java SDK SE 1.5 .
– Install MS Loopback adapter.
-Download WINRAR in advance.
-Chrome ( My favourite browser ). I’m simply not used to IE anymore and end up installing Chrome. WIll be helpful to keep it ready.
– Virtualbox – it’s useful to have the OS running as a VM for 2 reasons:
a) It’s easy to take snapshots at stages to revert to a working stage.
b) It’s easy to clone machines. I’ve got 2 clones now – one with a Win 7 VM which can be used to install anything and one with a functional SAP NSP system.
Software Installation Process:
– Have a fresh win7 installation ready – better use a base VM and clone it .
– It’s automatic to share resources between host and client machines on VMs – Copy all the software files to the client machine. Host is the base OS and by client I mean the one running on a VM.
– Install Winrar and unrar the software files.
– Install Java.
-MSLoopback adapter is already installed.
– Start SAP installation . It’s natural for it to log off and do a login again . I
– It will give some warnings about conditions not being met. They can be ignored.
– The installation took around 8 hours with step 16 ( import ABAP taking a lot of time ) . Hence, don’t panic if it stays there for along time.
– Install SAPGUI and add NSP to logon .
– You start the system from SAP MMC.
– I wasn’t able to modify the system params ( icm/host_name_full ) from RZ10 . So I just changed the file at OS level directly and restarted SAP .
– Ensure that the host name ( FQDN ) has a .com ( or dot<something> ) as ABAP checks it while trying to get the host etc and you’ll get a short dump .
– SAP help lists all the services required to be activated .
– If the system is timing out on you ( as it’s not very powerful ) , you can increase the timeout for HTTP service from transaction SMICM :-> Go To Services -> Chose HTTP and change time etc.
This version is definitely better ( and more stable in installation ) compared to the previous ones . It has never failed on me .It has Gateway though I haven’t really done anything with it yet.
Installing license keys and developer key for BCUSER.
– I removed the existing license keys as the system name is SAP-INTERNAL and the access keys for BCUSER seems to take an issue with it.
– Go to SLICENSE, remove the license keys and install the new one ( chose the first NSP from the license key request page ) .
– Once the license is installed, you can then try to create custom objects and enter key for BCUSER.
Troubleshooting adapter module JCo RFC calls
Posted: February 2, 2014 Filed under: SAP, SAP ABAP, SAP Java, SAP PI/PO | Tags: ABAP, java, SAP, SAP PI Leave a commentFrom my blog on SCN – http://scn.sap.com/community/pi-and-soa-middleware/blog/2013/12/23/troubleshooting-adapter-module-jco-rfc-calls
Many a times we have adapter modules ( AM ) which in turn do a RFC call to ABAP stack of the XI system to retrieve information. This can be handy to make a generic AM that can be plugged in for multiple interfaces.
As an example, if we already have a text file with idoc data in plain text format, the adapter module can be used to convert this data into idoc format. The ABAP stack FM can be created to inquire idoc metadata information in IDX2 and use it to create the idoc structure.

The different steps are as follows:
1.This step shows the data being processed in the module chain. It’s represented in hex format for the message. So, if we have a text file with content “hello” – the message will be “68 65 6c 6c 6f”.
2.The message is entering the module chain. It can be after reading the file for a sender FTP adapter if this is the first module or after another module call e.g. for code page conversion.

3.As part of the adapter module processing, a RFC call is made using Java Connector ( JCo ) with the message and other parameters. These will be adapter module parameters.
4.The returned message is idoc data in hex format of the XML stream.
5.The message is leaving the adapter module.
6.The data is in hex for the idoc. To make it simple, if the idoc data is “<hello>” the message here is “3c 68 65 6c 6c 6f 3e”.
In the above diagram, the module parameters are sent to the RFC function module in text format though the message data will be hex.

Link:http://help.sap.com/saphelp_nw04/helpdata/en/9a/20e23d44d48e5be10000000a114084/content.htm
With all the above theoretical knowledge, let’s create a simple Java program that can aid in troubleshooting.Pre-requisite Libraries to be added to our project:
1. Google Guava :
Get it from here – http://code.google.com/p/guava-libraries/
2. JCO libs
Get it from service marketplace.
3. Create a jar with the property file: I’ve provided a sample property file. It has the details to make us connect to the host, authenticate
Files to be created:
1. Props.properties : to store connection / authentication details so that it’s easy to change the target instead of hardcoding the values in the program.
2. PropHelper.java : Helper class to read properties file.
3. simulateRFCBean: This is the main class – it’s used for reading the file and making the JCo RFC call.
The steps will be:
1.Check the function module for parameters of type IMPORT (or ask your friendly ABAP colleague about the function module.)

This FM requires two parameters:
SOURCE (the message sent as hexadecimal stream).
SNDPRN (This is a just normal text)
The names won’t have to necessarily match as within the module, we map parameter ‘partner’ to ‘SNDPRN’ for the RFC call.
2.Map the data types to Java using the table mentioned above.
Looking at the function module and the data mapping, we’ll need to
a) Convert the file contents to a hexadecimal string ( byte array in Java )
b) Send the sending system as a string ( String in Java )
3.With the above information, it’s straight forward to create the Java program.
a)Read the JCO properties – PropHelper.java is a helper class to help read these properties instead of hardcoding in the program.
b)Read the file to be checked and convert to byte array.
byte[] fileData = Files.toByteArray(new File(“C://temp//bad3.txt”));
– Do the necessary JCO Set up, set the parameters to be supplied for the RFC call
function.getImportParameterList().setValue(“SOURCE”,fileData);
function.getImportParameterList().setValue(“SNDPRN”,”TESTSENDER”);
and finally, make the call.
function.execute(destination)
Now with the set up done, we’re able to replicate the error scenario.
The issue on the communication channel log indicated.
![]()
Using this program, we’re able to replicate the failure.

For debugging on ABAP, an external break-point needs to be set up in the called function module.

Some of the error scenarios we encountered:
- Bad data – new line appearing in the message.
- IDX2 configuration missing for the unique message combination – existing for the basic type and an extension.
However, once we’re able to simulate the failure and debug the issue, finding the resolution is much easier.
Sourcde code link : https://github.com/viksingh/SimulateRFCCalls
Antifragile software
Posted: February 1, 2014 Filed under: SAP, Software | Tags: ABAP, Nodejs, SAP Leave a commentFrom my blog on SCN – http://scn.sap.com/community/abap/blog/2013/12/01/antifragile-software
Before proceeding further, I have a confession to make – it has mostly nothing to do with ABAP development and it even spans other areas of SAP. For simulation of fault tolerance systems, I used non SAP software However, as it concerns software development and in SAP space what better subspace than ABAP to get opinions of developers, I’m putting it in ABAP development. Hopefully it will be of some use.
I recently read “Anti-Fragile” from Nicolas Nassim Taleb and it kept me wrapped till my eyes were hurting. It is a very good read even though I may not agree with all his notions. Taleb coined the term ‘antfragile’ as there was no English word for what he wanted to express, though there’s a mathematical term – long complexity.
Taleb categorizes objects in the following triads:
– Fragile : This is something that doesn’t like volatility. An example will be a package of wine glasses you’re sending to a friend.
– Robust : This is the normal condition of most of the products we expect to work. It will include the wine glasses you’re sending to the friend, our bodies ,computer systems.
– Antifragile: These gain from volatility. It’s performance thrives when confronted with volatility.
Here volatility means an event that induces stress.If fragile loses from volatility and robustness merely tolerates adverse conditions, the object that gains from volatility is antifragile. Our own bodies are healthier over time with non linear exposure to temperature and food. Our immune systems become better when attacked by disease. And as it’s now obvious in Australia, small naturally occurring fires prevent bigger fires. Spider webs are able to resist winds of hurricanes – a single thread breaks allowing the rest of the web to remain unharmed.
Taleb’s book mostly considers the notions of fragility and antifragility in biological, medical, economic, and political systems. He doesn’t talk about how this can apply to software systems but there are some valuable lessons we can draw when it comes to software systems. Failures can result from a variety of causes – mistakes are made and software bugs can be in hibernation for a long time before showing up. As these failures are not predictable, the risk and uncertainty in any system increases with time.In some ways, the problem is similar to a turkey fed by the butcher – for a thousand days, the turkey is fed by the butcher and each day the turkey feels that statistically, the butcher will never hurt him. In fact the confidence is highest just before Thanksgiving.
Traditionally we have been designing software systems trying to make them robust and we expect them to work under all conditions.This is becoming more challenging as software is becoming much more complex and the number of components is increasing. We use technology stacks at higher levels of abstractions. Further, with onset of cloud, there might be parts which are not even in your own direct control. Your office might be safe but what happens if data centers where the data and applications reside get hit by the proverbial truck.
We try to prove the correctness of a system through rigorous analysis using models and lots of testing. However, both are never sufficient and as a result some bugs always show up in production – especially while interacting with other systems.
For designing many systems, we often look at nature – nature is efficient and wouldn’t waste any resources. At the same time, it has anti-fragility built in – when we exercise, we’re temporarily putting stress on body. Consequently, body overshoots in it’s prediction for next stressful condition and we become stronger.If you lift 100 kg, your body prepares itself for lifting 102 kg next time.
We spend a great deal of effort in making a system robust but much in making it antifragile.The rough equivalent of antifragile is resilience in common language – it is an attribute of a system that enables it to deal with failure in a way that doesn’t cause the entire system to fail. There are two ways to increase resilience in systems.
a) Create fault tolerant applications:The following classical best practices aid in this goal.
– Focus is better than features: Keep classes small and focused – they should be created for a specific task and should do it well. If you see new extraneous features being added, it’s better to create separate classes for them.
– Simplicity is better than anything: Keeping the design simple – It may be fun to use dynamic programming using ABAP RTTI / Java Reflection but if it’s not required, don’t do it.
– Keep high cohesion and loose coupling: If the application is tightly coupled, making a change is highly risky.It makes the code harder to understand as it becomes confusing when it’s trying to do two things at the same time ( e.g. try to do data access and execute a business logic at the same time ). Any change to the business logic change will have to rip through data access parts. As an example, whenever the system needs to communicate with an external system ( say you’re sending messages via an ABAP proxy to PI / some external systems ) , keep the sending part as a V2 update. You don’t want to block the main business transaction processing or hang on to locks.If there are issues with the receiving system being slow or non available, it’ll ensure that your main business document processing doesn’t get affected.
And keeping fault tolerance in mind, the following ideas can help.
– While putting any new code in production, make it unpluggable in case things go wrong.
– Create tools to deal with scenarios when things go wrong. Taking the example scenario when we’re not able to send messages as the external system is down / unable to keep up with the throughput, we should have transactions that can resend these messages after identifying them.
Replica Sets and Sharding: As developers we may not have to worry about too much building fault tolerant infrastructure but it’s helpful to know the following concepts.
– Replica Sets: Create a set of replication nodes for redundancy . If the primary node fails the secondary nodes get activated as primary. For instance, in a three node scenario we can have a primary where all the writes happen ( in green ) and the secondaries ( in red )are asynchronously updated. In case the primary fails, one of the secondaries can become the primary. There can be further variations where reads can be delegated to secondaries if freshness of data is not a concern ( e.g. writes to some data set happens very rarely or at times when the likelihood of application requiring data is very small ).

For simulation, I created a replication set and made the primary node fail. This is how things look when things are going on smoothly . dB writes are issued and the callbacks confirm that the write is successful.

Now, I made the primary node fail so that the secondary becomes the primary. We’re issuing inserts but as the secondary takes some time to become primary, the writes are cached in the dB driver before it gets completed and the callbacks confirm of the update.

Sharding: It’s a horizontal partition of data – i.e. divide the data set into multiple servers or shards.
Vertical scaling on contrast aims to add more resources to a single node which is disproportionately more expensive than using smaller systems.

And sharding and replica sets can be combined .

Integration: Here again, some very simple things help a lot.
– Keeping the communication asynchronous – while designing integration always assume that the different parts will go down and identify steps needed to control the impact. It’s similar to the earlier example of primary node failing .
– In queuing scenarios, bad messages to be moved to an error queue. Thankfully this feature has been added in SAP PI with 7.3X .
However, there is a class of errors that we’re still susceptible to – anything which has a single point of failure. And these could be things external to your application – your firewall configuration etc.
Digital circuits achieve fault tolerance with some form of redundancy .An example is triple modular redundancy (TMR).

The majority gate is a simple AND–OR circuit – if the inputs to the majority gate are denoted by x, y and z, then the output of the majority gate is . In essence we have three distinct pipelines and the result is achieved by majority voting.
Application integration with ESB is definitely better than using point to point communications but it’s susceptible to single node failures. May be need a more resilient integration system?
b) Regularly induce failures to reduce uncertainty: Thinking of fault tolerance in design certainly helps but there can always be certain category of problems that come with no warning. Further, the damage is more if a service breaks down once in five years than a service which fails every two weeks. Hence, the assertion is that by making it constantly fail, the impact can be minimized. ‘DR tests’ in enterprises are an effort in that direction. However, what happens if we don’t want the failure to be like a fire drill. And in fact most failures in future are going to be the ones we can’t predict. Companies like netflix are already using this strategy. They have their own Simian Army with different kinds of monkeys – Chaos Monkey shuts down virtual instances in production environment – instanced which are serving live traffic to customers. Chaos Gorilla can bring an entire data center and Chaon Kong will bring down an entire region. Then there is latency monkey – it causes addition of latency and this is a much more difficult problem to deal
Mobile Development and Antifragile
My experience with mobile development is only for the last couple of years but there are some distinct patterns I can see here. The languages, frameworks, technologies etc. are fun than some of the broader points that emerge are:
– Being antifragile is a feature: The expectation of users is to have the application performing even under volatile conditions – bad / low internet connectivity. We went in the application with a lot of features and then cut down to make it more performant – this was the most critical feature.
– Parallels between antifragile and agile development. Agile processes have short iterations, test driven design and rapid prototyping – they all indicate that failure is inherent and the best way to get out of it is to acknowledge and learn from it to make corrections. In some ways, agile is more honest than the traditional methods where we think we can calculate all the future estimates, know all the risks and know what’s going to fail. The emphasis is on failure being a source of strength than something to be hidden assuming it’ll never be discovered.
Cloud and Antifragile
I’ve very limited experience with cloud and none of it is in production- AWS for developer machines , using SAP’s HANA trial for the open sap course and another provider for trying out some other technologies. I can see two big benefits :
– It’s easier to try out new iterations making the software development process more agile.
– If a component fails, it’s easier to replace them.
Thinking of Failure
Moving to the original notion of what’s the most useful – it is the notion of failure . An antifragile way of developing software does require a shift in way of thinking though.Some of the more important ones being :
– Seeing ‘bugs’ differently : Bugs should be seen as how the system functions under certain situation and the emphasis on what we can learn from it.
– Adoption of a ‘blameless’ culture : Follows from the law of unintended consequences. We create incentives for people to come out as perfect who never fail and consequently we annihilate any change, sometimes slowing down to the extent where we can’t even get much needed changes.
These were some of my thoughts. Like any way of thinking, it may not be an elixir but there are valuable lessons in being antifragile.
Job Scheduling on SAP PO ( SAP PI Java stack )
Posted: February 1, 2014 Filed under: SAP, SAP Java | Tags: java, SAP PI, SAP PO Leave a commentFrom my post on SCN : http://scn.sap.com/community/pi-and-soa-middleware/blog/2014/02/01/job-scheduling-on-sap-po-sap-pi-java-stack
Job Scheduling on SAP PO ( SAP PI Java stack )
Scheduled jobs are one of the most common mechanisms to carry out repetitive tasks. In SAP ABAP stack, we have a comprehensive functionality to schedule jobs in SM36/SM37 etc.
With SAP PO being a SAP AS Java system, there is a need schedule jobs to carry out repetitive housekeeping tasks. However, there could sometimes be additional information to be sent out from SAP AS Java system – an example could be custom information from SAP AS Java tables. There’re web services creates by SAP but in some situations they may not be comprehensive enough for our requirements and hence a way needs to be found to send this information out regularly.
The below diagram describes our requirement – the system on left is SAP PI Java stack.
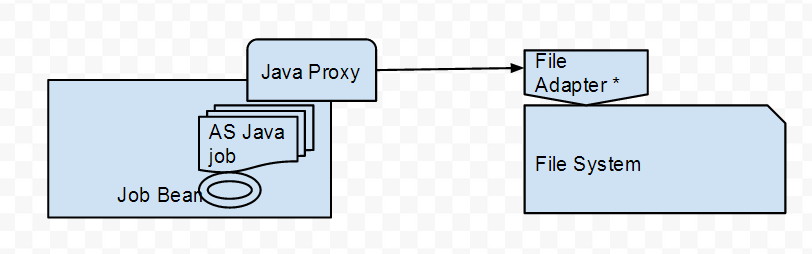
On the receiving side, it can be replaced by a different mechanism – e..g ABAP proxy if sending the information to an ABAP system.
Steps.
1. Generate proxy for outbound interface: The steps are already described in my previous blog.
We’re using asynchronous mechanism in this case .Verify that Interface pattern is Stateless.
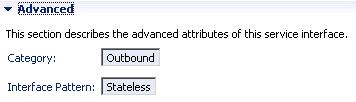
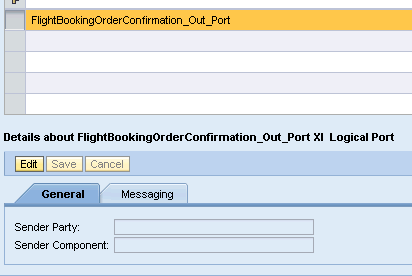
Initially I tried using a service interface with Stateless ( XI 3.0-Comptabible) but the generated proxy won’t have XI logical port .


Where as for FlightBookingOrderConfirmation_Out we get a XI Logical Port.
.
After this step, we have a web and an EAR project.
2. Generate a Job Bean : Create a normal EJB project and then use NWDS options to create a new “scheduler job”.
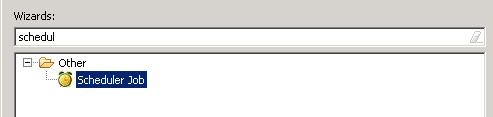
It’ll create an EJB project with a class file to write the logic for our job and extra descriptor files based on values provided in wizard.
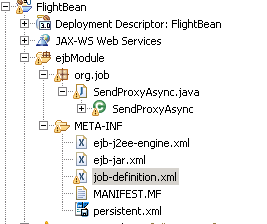
job-definition.xml is a descriptor unique for jobs and holds the job name.

It should match the values generated in the Java file.

Looking at the SendAproxyAsync.java where we implement the job execution logic, add the Proxy Service name.

Main parts of this class:
Logger can be created to log information useful in troubleshooting issues.

and of course any errors can be logged.
Now, do the usual bit – create XI contect objects, update business data to be sent out and do the outbound proxy call.
Deploy this project.
3. Create an iFlow for this scenario – Nothing too complicated here .We need to create an iFLow for the sender / receiver / interface values. Make sure that the sender communication channel has XI as the message protocol.
4. Set up in NWA:
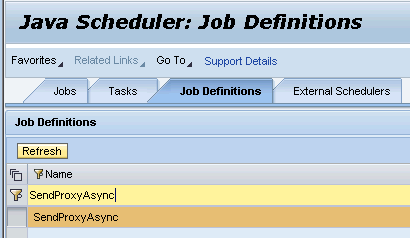
We can look at the job definition in NWA by going to Java Scheduler -> Job Definitions.
As we have already deployed our project, we can see the job definition here.
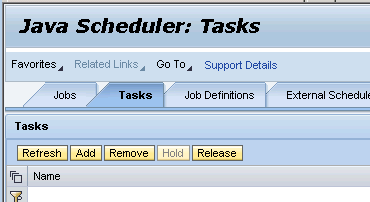
To start executing the job, we need to create a task specifying conditions ( as begin / end time / recurring frequency etc ) .
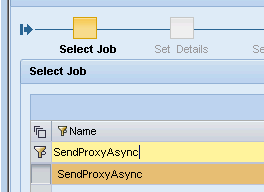
We select our job and complete the wizard – it’s similar to what we’ll give in SM37 on ABAP stack.
After this step, the jobs will start executing at the specified frequency.
5. Testing:
‘’The executed jobs can be checked in the tab “Jobs”.
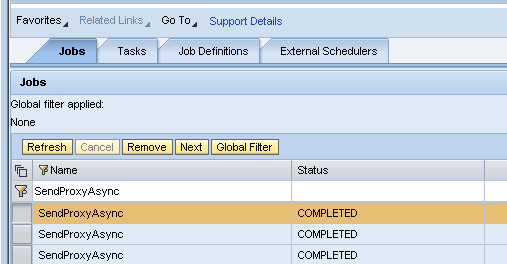
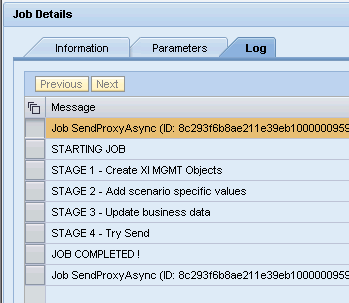
And a log can be displayed with the various messages we have put in the Job Bean – similar to messages on ABAP stack.
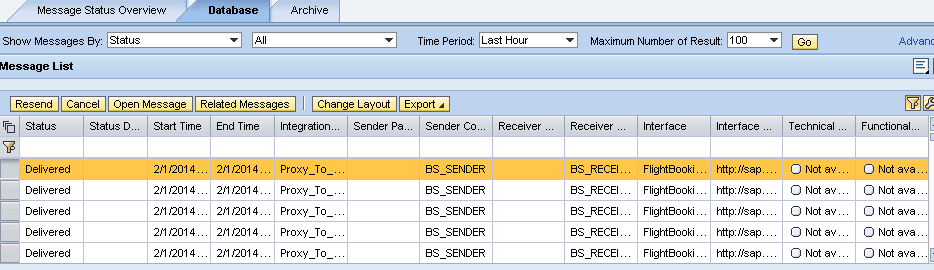
Verification : Navigate to PIMON and check messages
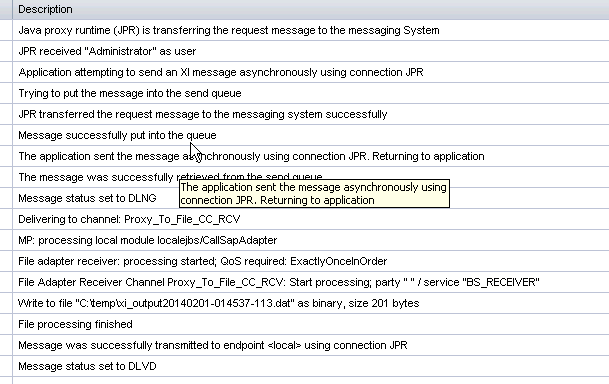
Logs confirm it’s working fine.
The code is at https://github.com/viksingh/PIJavaProxyAsJob . I’ve put the code for only the Java file as others are generated by wizards. For
troubleshooting, looking at system Java logs .
Implementing Sender Receiver Java proxy scenario in SAP PO/PI
Posted: February 1, 2014 Filed under: SAP, SAP Java, SAP PI/PO | Tags: java, SAP PI, SAP PO Leave a commentFrom my post on SCN – http://scn.sap.com/community/pi-and-soa-middleware/blog/2014/01/28/implementing-java-proxy-scenario-on-sap-po
I have been doing some work of late with Java proxies on SAP PO .I tried to use product documentation to understand their working. Product documentation is always the best source of information but things are much clearer for me after I’ve already developed something using a concrete example.
I hope that this post will be useful for anyone trying out SAP PI Java proxies. Here both the sender as well as receiver are Java proxies and it has been implemented on a 7.31 SAP PO system.
Scenario: We’ll use the flight demo model scenario with two Java proxies – interfaces FlightSeatAvailabilityQuery_Out_new for outbound service call and FlightSeatAvailabilityQuery_In_new for inbound service implementation.
Broadly, we’ll have three major objects:
Sender Proxy ( Consumer ) – Being sender, this proxy doesn’t provide any service but is used to make the outbound service call.
Receiver Proxy – It has the actual service implementation .
Servlet ( for testing ) – As the proxy calls are to be in an JEE environment, we’ll create a simple Servlet for testing.
At a high level, the below diagram shows what we’ll end up creating. We’ll need to create a configuration scenario as well but that shouldn’t cause too much grief.
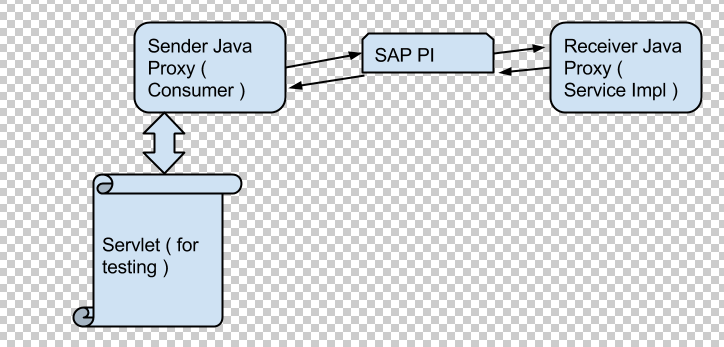
We need to create the below projects in NWDS. The names in italics are our project names.
a) Dynamic Web Project ( JavaProxyWeb ). This will hold consumer proxy (sender objects) and servlet used for testing.
b) EJB Project ( JavaProxy ) : This will hold service implementation on the receiver side.
c) EAR (JavaProxyEAR) – EAR to deploy JEE objects.
So we have the below three projects to start our work..
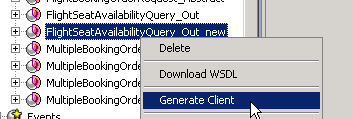
Consumer Proxy Generation
Let’s generate code on the sending side ( consumer proxy ) . We don’t want to chose a Javabean as there is no actual service implementation. We’re just generating client to call our proxy and hence chose “Generate Client”.
.
In the next screen , check the values of Server/ WebService runtime and verify your Dynamic Web Project and EAR project are chosen.
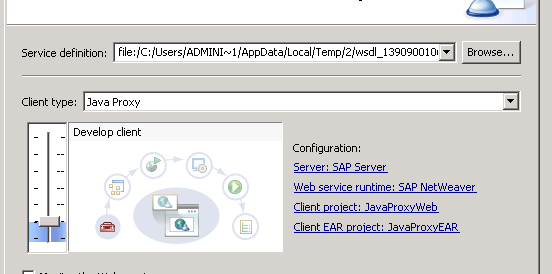
And we don’t have to WSDL as we’re not really using the end-points for any service all . We’ll be creating a configuration scenario in PI Designer to generate the configuration.
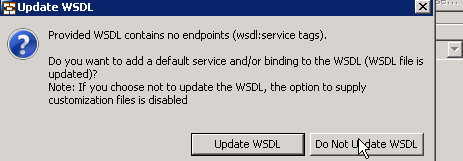
After that, let the wizard go through default values and just press finish.
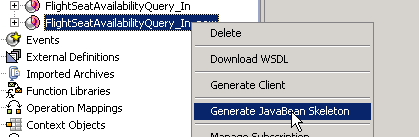
Inbound Service Generation
For our inbound service implementation, let’s take the corresponding service interface. This time we want to generate a bean and hence chose “Generate JavaBean Skeleton”.
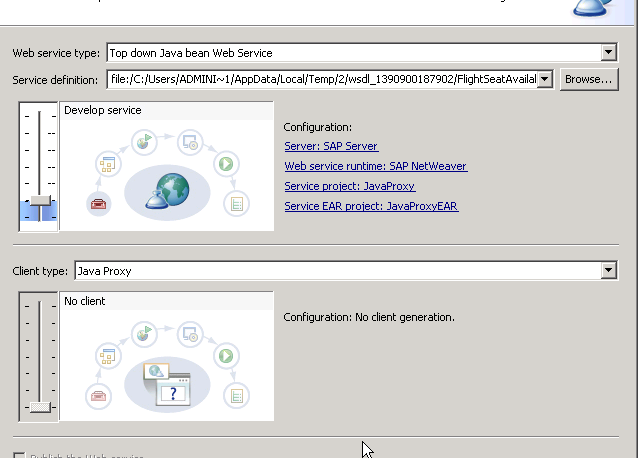
And as we’re not really going to use any client, we can move the slider for client to minimum and just generate the shell for the Web Service.
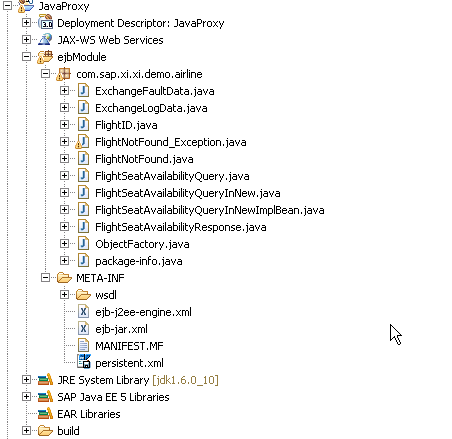
Our EJB project looks something like this.
And the web project should look similar to this.

Adding Servlet to web project ( for testing )
As we need a servlet for testing, let’s create one in our web project.
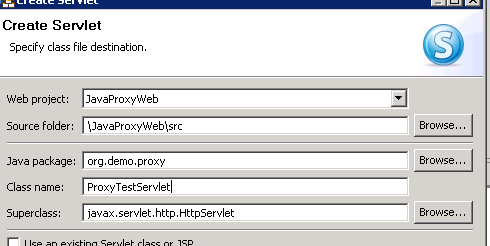
Additions to servlet which makes the outbound proxy call object
Add the WebService annotation with the service name and create an instance of the Service.

This is the outbound service call. We need to create an instance of port and as we’re using XI as the message protocol, we need to use methods from XIManagementInterface.

and the actual proxy call to get the result.

We have set the business system programmatically. It’s also possible to not set it here and instead set Party and Sender Service in configuration for Java proxies ( this appears once the project is deployed ) in Port Configuration.
Inbound Service Implementation
For the inbound service implementation, we’ll need to add @XIEnabled annotation and it’ll need @TransportBindingRT as well. Add @XIEnabled and IDE will help with @TransportBindingRT as they’re required together.

Project Deployment
Our EAR has our EJB as well as dynamic web project.Deploy the EAR .

Service verification in NWA
Once the project is successfully deployed, we should be able to find our consumer proxy . This was actually confusing for me. I tried to deploy the generated client without the actual service call in servlet and it never worked for me. Only when I created the servlet making the outbound call I could see the outbound proxy. It’s best to finish outbound proxy and inbound service implementation along with consumer application ( servlet in this case ) and then try to deploy them in one shot.
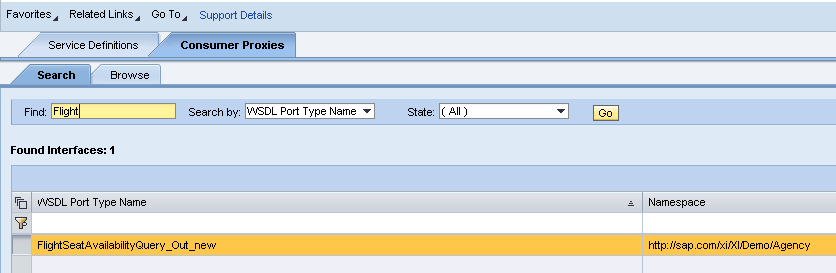
Below is the screenshot of the port configuration . We can set the party/ business system here if it’s not set programmatically.
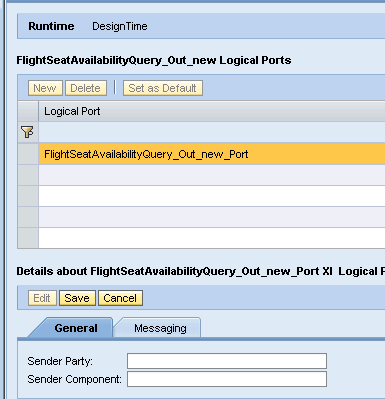
Similarly, the inbound service shows up as well in Service Definitions.
Our development is done. Now, we need to create an integration flow with the required sender / receiver interface values.
Sender communication channel uses XI message protocol for a SOAP adapter and HTTP as the transport protocol.

Similarly, create a receiver communication channel of type SOAP, using HTTP as transport protocol and XI as message protocol.

Path prefix for sending proxy messages bia JPR is /MessagingSystem/receive/JPR/XI.
Do a test with the URL going to be used on the receiving side to verify it’s running.
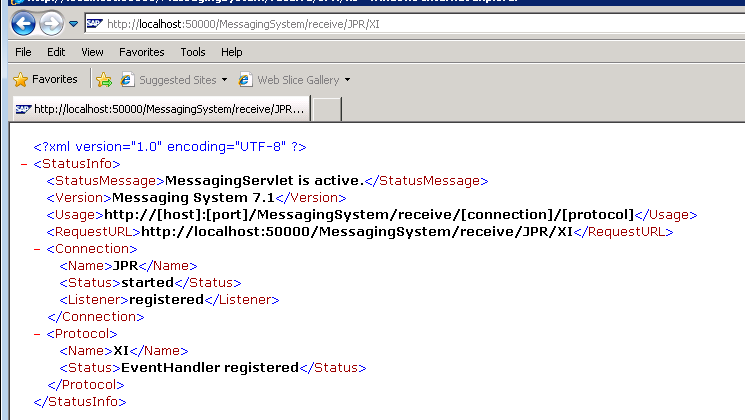
Now, configure the receiver communication channel. Change the authentication mode to “Use logon data to no-SAP system’ and provide
authentication credentials.

Activate the iFLow and we’re ready to test the set up.
Testing
Fire the servlet and it should come up with the below screen
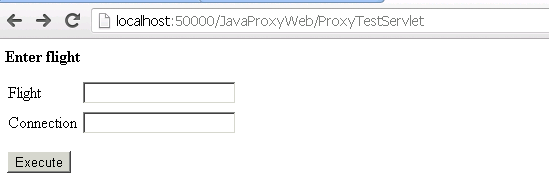
Put your flight and connection details. We aren’t really using the date and hence it’s not in screen.
And if everything goes well, we should get the below screen.
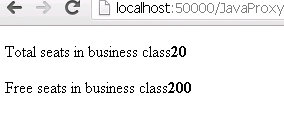
Voila ! Our proxy worked and it has come back with the response.
This matches with our service implementation – we’re just returning 20 free and 200 max business class seats .

The message can be displayed in RWB / PIMON.

The audit log confirms that JPR has successfully delivered the message along with the response message.
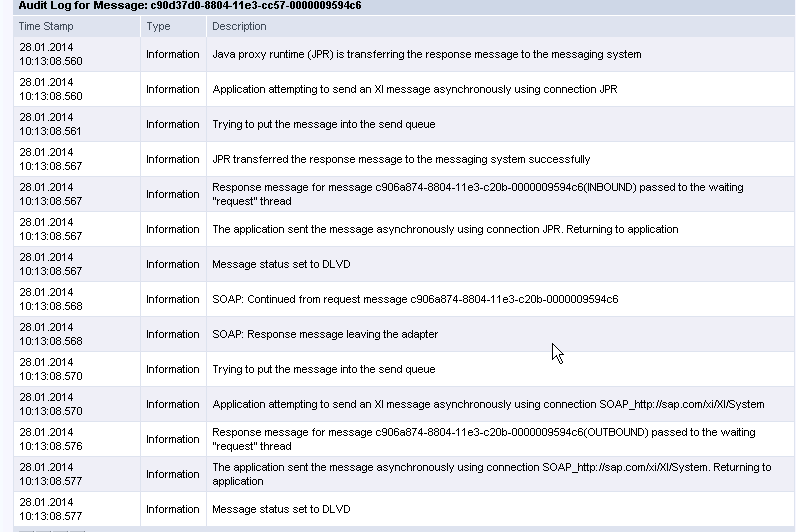
The source code is available on https://github.com/viksingh/PIJavaProxy . I’ve just put the outbound proxy call in the servlet and the inbound service implementation as these are the two files we need to modify. Rest all were left standard including deployment descriptors.
Debugging Java applications on SAP PI/PO
Posted: February 1, 2014 Filed under: SAP, SAP Java | Tags: java, SAP PI, SAP PO Leave a commentFrom my post on SCN – http://scn.sap.com/community/pi-and-soa-middleware/blog/2014/01/25/debugging-java-applications-java-mapping-java-proxies-etc-on-sap-pipo
Below are the steps to debug any Java application on SAP PI/PO – they are generic for SAP AS Java server .It can be used to debug Java mappings, Java proxy calls in PI etc.
-Log on to SAP management console and click on developer trace. There is documentation of SAP AS Java ports here.
http://help.sap.com/saphelp_nwpi71/helpdata/en/a2/f9d7fed2adc340ab462ae159d19509/content.htm
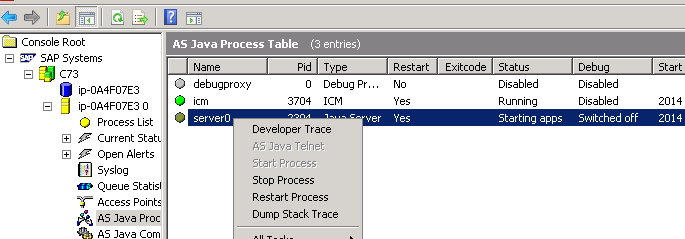
However, it’s easiest to just look at the Developer Trace and get the port number. You may need to ask Basis to supply this information as it requires access to SAP management console.
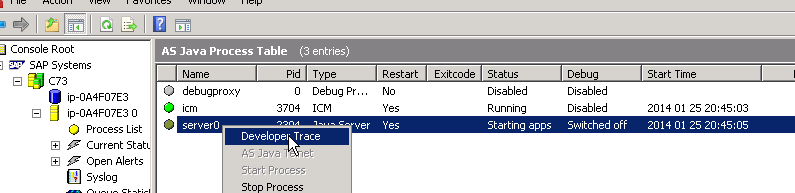
– In this case, the debugging port is 50021 .
– From SAP management console, enable debugging.

-The port number can also be verified by looking at debugging “Switched on (50021)” column.
– To debug the application, create a debug configuration in NWDS. It can be selected from Run -> Debug Configurations.
Use ‘Remote Java Application’ as the application type.


-Create the configuration specifying the project name and click on Debug.

– This launches the debug mode.Confirm to use the debug mode.
– We’re ready to start debugging the Java code.
The code can be any Java object :
– I tested with SAP PI Java mapping – in this case you have to let the map execute by processing a message.
– This example is a SAP Java proxy I was testing and had issues in figuring out the error. Hence, I created a simple Servlet which fires a message.

and the Servlet can be executed allowing us to debug any J2EE application component.


I hope it’s useful for SAP PI developers as especially with single Java stack, there are going to be more Java objects created and being able to debug is efficient.
Furthermore, in PI Java mappings sometimes we need the actual data and environment to test the application and making a dummy call from main to call transform / execute can’t doesn’t provide the information. An instance of this could be a JDBC call to read a PI table.
Use SAP DCs and SAPUI5 to build development objects for SAP PI/PO
Posted: February 1, 2014 Filed under: SAP, SAP Java, SAP PI/PO, SAPUI5/OpenUI5, Software | Tags: java, SAP DC, SAP Java, SAP PI, SAP PO Leave a commentFrom my post on SCN – http://scn.sap.com/community/pi-and-soa-middleware/blog/2013/09/26/use-sapui5-and-sap-dcs-to-build-development-objects-for-pi-731
PI 7.31 introduces a Java only version of PI. This obviously is much more efficient for message processing. However, many existing XI/PI customers have built processing logic on ABAP stack. In this blog, we’ll look at the steps that can be carried out to create similar functionality on Java stack. I hope the information will be useful and I welcome any suggestions/comments.
I’ll take a sample use case – dynamic receiver determination based on custom table entries. ( i.e. based on file name, route the message to different receivers ). For our discussion, the table will be very simple – it has three columns : id, filename and receiver. Id is primary key and filename is the field that is compared to pattern match with the message’s filename to determine the receiver business system. The table is too simplistic and data won’t be normalized but let’s ignore that for now .
Of course, it can be easily implemented using XPath expressions in PI 7.31 but I’m using this as it covers a functionality that was often implemented by clients on ABAP stack and it’s a good use case as we can use it to show usage of persistence. On ABAP stack, this functionality can be implemented using the following approach.
- – Create an ABAP class (with interface IF_MAPPING ) for processing logic where lookup on custom table is performed. This ABAP class is used in the operation / interface mapping.
- – SM30 can be used for table maintenance
- – SE16 can be used to display table entries.
As shown in the below diagram, a message may arrive / leave at Java stack but the scenario used ABAP development infrastructure. Of course, it was not mandatory but given ABAP skill set being more widespread in SAP landscapes we had the below situation in many cases.

So in a file to file transfer, the FTP adapters (on Java stack ) will receiver / send files and an ABAP map is used to perform lookup to find the receiver.
Option from PI7.31 onwards:

The following approach could be taken to create similar functionality on Java stack:
- Create tables in Java dictionary.
- Since SAPUI5 is supported by SAP AS Java and is the recommended UI by SAP, it can be used to build display and maintenance screens.
- – For server side processing ,we can use servlets to handle requests from SAPUI5 client. We’ll need two servlets – one to display data entries already in database and a second one to create new entries.
- – Receiver determination class is on Java stack where we can use Lookup API in a java mapping program. This is a normal Java map and can be built using DatabBase Accessor. I won’t cover in this blog but the github link for this project has the code which can be referred.
To keep the model simple, we can perform database operation in the servlet itself via JPA and not really go via EJBs. EJBs can be used for more complicated scenarios.
Additional Libraries Required:
- As it’s much more easier to use JSON with any Javascript library including SAPUI5, we’ll use Google GSON libraries to convert server side response to a JSON message.
Hence, our development objects will look somewhat like this.

We’ll use SAP Java Development Components ( DCs ) to leverage benefits of NetWeaver Development infrastructure for lifecycle management.
Some customers may still want to maintain the database on ABAP stack ( e.g. in their ECC system / SOLMAN etc .) and have it replicated to Java stack. In these cases, the messages can be sent to Java AS over HTTP via a RFC destination by tying it in with changes over ABAP tables. In case servlet expects/ returns JSON messages, we can use the standard ABAP class /SDF/CL_E2E_XI_ALERT_JSON_DOC / use SCN’s code exchange to get the JSON tool in case your ABAP system doesn’t have this standard JSON processing class.
In this case, the scenario will look like as below.

Implementation Steps ( our original scenario using SAPUI5):
- Google GSON libraries: Create a DC of type external library with Google GSON jar to package the required libraries. This is required as the servlet response will be in JSON format which can be easily interpreted by the client side SAPUI5 JavaScript code.
- – Create a DC for external library and add the jar file to libraries folder.

Change the access to allow access for both COMPILATION as well as ASSEMBLY.

- – Ensure that both public parts have jars.

2. Create a dictionary DC. It’ll have an ID column and FILENAME and RECEIVER columns. Based on FILENAME, we’ll determine the RECEIVER.

Create dictionary and deploy it to SAP Java Server.

- – Create an additional TABLE for generating keys. We’ll use this later for primary key generation.

- – Verify that the table exists on database. You may switch to database development perspective. Create a connection using your dB connection details.

3. Create an EE application of type “Web Module” and perform the following steps:
- Add JPA support by modifying project facet.


- – Generate entities from tables. This will generate a class for the database table.


It should already have the below annotation.

As we’ll use key generation from a different table (TMP_KEYGEN) , the below annotations are required.

Update persistence.xml to change the transaction type as Local as we’ll be managing transactions in servlet code while persisting data.

- Add SAPUI5 libraries – Refer to the below blog for detailed steps.
- http://scn.sap.com/community/bpm/blog/2013/01/14/developing-sap-ui5-applications-in-sap-netweaver-developer-studio–part-22
- In summary:
- Add SAPUI5 SCAs and put dependency for both the DC as well as the SC.
- Add SAPUI5 Javascript libraries.
- Add SAPUI5 Java libraries.
- Update web.xml to add components required for SAPUI5
- – We’ll create two servlets: RetrieveData will display existing table entries and UpdateData is used to create entries. Both servlets will need to have the JPA information injected at runtime and hence we need the following annotation / declaration.

RetrieveData servlet will return all values in the database.

- – UpdateData inserts values to the database table:

write( response, map ) is a helper method has been written to write the JSON response – it’s the last 3 lines of the previous servlet.
Nothing too fancy in html file – it calls the main view.
![]()
I won’t go throught the entire JS code. Essentially it builds the views shown later below. The Javascript code invokes GET method on RetrieveData servlet. Here, we invoke a GET method on RetrieveData servlet and push the result into an array which can later be bound to a table that will be displayed.

And code to trigger POST. We just display an alert message .

Java files structure for the web module:

and files for UI in the web module:

This is how the project DCs look.

Dictionary DC was created and deployed separately as it doesn’t have to be part of this EAR.
jsonlib: Has Google GSON libraries for Java processing.
detcvr: It’s the webmodule – It has servlet , views as well as JPA generated entity file.
dtrcvear: It is our EAR to deploy the application to SAP AS Java.
This is how the screen turns out to be. We can maintain values :

And entries are dsiplayed using the “Display Routing Values” tab.

To test in PO, create an iFLow with two receivers, one default and the second one will be determined based on Java map which will perform a lookup on the table to get the receiver business system based on filename. Configure Routing with Dynamic Message Router

and process two files: First with an arbitrary name and second one has name starting with IN which was updated in our dB by SAPUI5 application. Based on the table entry, the message is routed to BS_DUMMY_IN business system.
![]()
The code for this project can be referred at https://github.com/viksingh/PIDYNAMICRCVDCs .
Reducing integration effort by leveraging SAP enterprise services part2
Posted: February 1, 2014 Filed under: SAP, SAP ABAP, SAP PI/PO | Tags: SAP ABAP, SAP PI, SAP PO Leave a commentFrom my post on SCN – http://scn.sap.com/community/pi-and-soa-middleware/blog/2013/06/04/reducing-integration-effort-by-leveraging-sap-enterprise-services-part2
This is in continuation of the first blog on reducing integration effort by using SAP enterprise services (http://scn.sap.com/community/pi-and-soa-middleware/blog/2013/06/04/reducing-integration-effort-by-leveraging-sap-enterprise-services )
I’ll describe the steps in more detail here.
Step1. Identify services required.
Go to http://esworkplace.sap.com/ and identify the service required. There’re various ways you can navigate the content. If you’re implementing a new scenario, typically a complete process , you can use integration scenarios ( e.g. agency business ) . Using solution map is higher level ( e.g Sales Order Management ) . Business Scenario Description seems hybrid of the above two and I prefer that. Then, in each bundle you can navigate to the service operation and read through the documentation. Make sure the selected operation is not deprecated. SAP has good documentation around features, configuration required in backend system, error handling and any business function required.
Step2. Identify system set up requirements
Identifying all operations will help to come up with a list of requirements for system set up. It’s relatively straight-forward in PI as we just need to import the software component. However, for the back end system, there can be couple of scenarios:
– Service requiring business function activation (e.g. SAP APPL 6.04 requires LOG_ESOA_OPS_2 activation) .
– Service requiring add-ons to be installed by BASIS in SAINT transaction (e.g. ESA ECC-SE 604 requires BASIS to install ECC-SE add on).
Get the ECC activities organised (as mentioned in part1, some of the business functions are irreversible) and import corresponding PI SWCVs into ESR – these could be downloaded from SMP and imported as usual.
Step3. Check components are completely installed in the system.
Go to transaction SPROXY. If the ECC system satisfies all the pre-requisites and PI has the components as well, the SWCVs should appear in transaction SPROXY.

In SLD, the ECC technical system should have the additions appearing as a software component version in Installed software of the ECC technical system.

Step4. Create custom software component version. This is strictly not required but in experience, there’s always a need to customize messages and hence it should be created with the required service’s SWCVs as the underlying SWCV.

Step5. Test: Once the services are in ECC, you can use them to start doing testing.
Use transaction SPROXY for testing – this should help to identify the elements required in the message to be populated and the business documents processed. In experience, this is where you’ll spend the maximum time trying to identify what is required, where to populate the information etc.
You can test using SOAMANAGER as well but I prefer to just use SPROXY and then when the PI configuration is complete use SOAPUI.
Step6. There will be cases where the standard doesn’t fit the requirement completely. In that case, perform a data type enhancement in SAP PI in the custom namespace.

This should make the data type enhancement show up in ECC SPROXY. Creating the proxy here will update the ECC structures which are used by backend ECC classes for business document processing.

Step7. Some Hints: As usual, testing can be done by configuration in ID and using SOAP UI. Just couple of hints here:
Many of the standard services are sync and ensure that message logging for sync interfaces is on.
The messages appear in SXMB_MONI in ECC only when there’s an error (not application error but more like a system error like configuration, input message not conforming to length / type restrictions etc).
For debugging, you can create a comm channel with your username and turn on HTTP debugging if you’re trying to investigate the SOAP message (say headers).
Step 8: Special case: Lean Order being too Lean !
For one of the scenarios, while creating sales order we realised that lean order doesn’t have the fields we’re interested in. However, there’s a good document on SMP about “Enhancement Options for the Lean Order Interface” and it was very helpful
Step 9: Generate some positive karma – Do some good for people maintaining it later. As the development on ECC side is going to involve mostly enhancements, two things can really be useful.
– Keep all the enhancements in a composite enhancement.
– Create a checkpoint group so that it’s easier to debug messages.
Step 10: Logging in SAP: For synchronous interfaces, SAP does return the proper messages back to the calling application. However, the functional team doesn’t have access / interest to access PI to look at the errors. Hence, we had to build logic to update the messages as an application log (which can be checked in SLG1). This in some ways satisfies their requirement to look at the system to figure out what’s going on.
This is one area where perhaps either I’m missing something or SAP needs to provide information so that users / functional consultants can monitor the messages. Many functional consultants don’t want to even try to look at XML.
A simple class can be created to log the information and call them at appropriate enhancement points. However, we also created a generic method to convert any exception into a BAPI message.
Code can be referenced here.
https://github.com/viksingh/abaputilities/blob/master/exception_to_message_table
Couple of observations where things could potentially by improved by SAP.
– There should be a free tool by SAP to let users/ functional teams monitor messages during testing. I’m aware of AIF but don’t have experience as it’s not free.
– Lack of out of box support for JSON RESTful web service in SAP PI. The initial requirement was to use them but then the source application had to be modified to use CXF to generate SOAP web service calls on the calling application side. I was almost ashamed to go back to the third party
Some of the books & articles I found useful.
SAP Press Book: “Developing Enterprise Services for SAP”: Although I referenced this book only recently, I found an absolute joy to read and did pick up many things. This definitely helped to refine some of the ideas.
http://www.sap-press.com/products/Developing-Enterprise-Services-for-SAP.html
Enterprise Services Enhancement Guide
http://scn.sap.com/docs/DOC-18402
SOA MADE EASY WITH SAP
http://scn.sap.com/docs/DOC-17416
Blog-Add a field to LORD API
Reducing integration effort by leveraging SAP enterprise services part1
Posted: February 1, 2014 Filed under: SAP, SAP ABAP | Tags: SAP ABAP, SAP PI, SAP PO Leave a commentFrom my post on SCN – http://scn.sap.com/community/pi-and-soa-middleware/blog/2013/06/04/reducing-integration-effort-by-leveraging-sap-enterprise-services
The motivation of the blog is a conversation I had with couple of friends. They had implemented a new SAP functionality but were hassled by the amount of effort spent in integration. They eventually completed the task but after lots of crazy hours on late nights and sometimes weekends. As both the integration as well as the functional person is a friend and didn’t know about using enterprise services, I realised that perhaps not everyone is using enterprise services. Further, I was designing and implementing a solution to integrate SAP ECC with an external application for managing distributors and thought to write this post. Our integration required sending master data from SAP and transactional data updates in SAP ECC in OTC / P2P process area triggered from the external application.
Starting with the basics, look at the definition from SAP from BBA guide.
Enterprise Services: Web services using a common enterprise data model based on process components, business objects, and global data types, and following consistent communication patterns. SAP exposes software functionality as enterprise services.
There’s good documentation at http://esworkplace.sap.com/ .
In integration world, I see them as equivalent of classes in application development. If you’re able to use pre-existing content, most of the work is already done for you.
Why to go for enterprise services instead of trying to build them from scratch – what are the practical benefits?
– Leverages pre-built solutions reducing in substantial development effort reductions. We were able to reduce development effort to around 60% of initial estimates and even this is high because of the first time efforts in understanding their architecture and doing some prototyping.
– Easy to extend: Any project will require customization not delivered by standard solution and normally making changes later on is very time-consuming. Most of the functionality is already covered and even if additional changes are required – SAP has given a nice framework to customize them first in PI and then carry out adjustments on SAP system in ABAP stack.
– Comes with a lot of bells and whistles: Have error handling, data validation pre-built.
The following points need to be considered though:
– We utilised various software component versions and there were two mechanisms to get them installed in our landscape.
a) Some require installation of an add-on in ECC requiring BASIS effort (e.g. ECC-SE add-on to be installed by BASIS).
b) Others require activation of irreversible business functions (e.g. ESOA_OPS01 for services in SAP APPL). It’s important to understand that some of the business functions can’t be reversed and hence some amount of regression testing of affected areas need to be performed. SAP provides a test catalogue about the impacted functionality which can help in determining the impact. We tried them first in sandbox. Initially the activation didn’t go smoothly resulting in ABAP dumps which go away on activation. However, it’s painful as you have to wait for a transaction to dump before activating it. After an OSS message, finally we regenerated all programs of EA-APPL, ECC-SE and SAP_APPL software components.
At a very broad level, there are 5 different activities that need to be done.
i ) Identify which services meet requirements completely ( or to the largest possible extent ). There can be more than one service for a given business function ( e.g SalesOrderERPCreateRequestConfirmation_In_V1 and SalesOrderERPCreateRequestConfirmation_In_V2 for sales order creation ). I noticed two things: The former wasn’t able to meet all our requirements and has been deprecated as well. Like any other artefact in software engineering it’s best to avoid deprecated services.
ii) PI configuration: This was straight forward in our case as it was simple SOAP to proxy and reverse.
iii) Back end ABAP adjustments: These were made to fill in organizational data as the third party system doesn’t have concept of some of the organisational structure, data etc.
iv) BASIS activities: Installation of add-ons (e.g. ECC-SE add on via SAINT), regeneration of affected ABAP programs via SGEN.
v) Co-ordination of regression testing: This may involve change management, regression testing and functional owner of the application / process area.
Some of the points we learnt from experience:
– Be ready to spend time in advance of the actual development in prototyping and investigation. However, it pays back in later stages of projects.
– We had to build application logging on ECC side so that in case of errors a functional person knows what to look for.
– There was one instance where we had to overwrite SAP solution. Fortunately, it can always be over-written as a post-exit method in the implementing ABAP class.
– Update some of the system parameters ( e.g. icm/keep_alive_timeout parameter in downstream PI systems). While transporting ESR contents, we realised that the transport import was failing after 5 minutes. These ESR transports with stnadard SAP content can get really big and it’s best to send them in separate transports (for each SWCV) . Our first attempt in trying to import them took 22 minutes in total!
In part2, I’ll describe the steps in more detail to make the implementation process clearer but from our experience, SOA is definitely not dead!
Link to part 2 : http://scn.sap.com/community/pi-and-soa-middleware/blog/2013/06/04/reducing-integration-effort-by-leveraging-sap-enterprise-services-part2
PI adjustments for app and dB server split
Posted: February 1, 2014 Filed under: SAP, SAP PI/PO Leave a commentPosted from my blog on SCN : http://scn.sap.com/community/pi-and-soa-middleware/blog/2013/05/23/pi-adjustments-for-app-and-db-server-split
Recently, I was involved in a project with the goal of splitting app server and dB to split them on different hosts. If app and dB server are on the same host, there’s no confusion as there’s only a single host. However, if in case of dB and app server split, dB host should be taken for technical systems.
We got following errors after app/dB split.
– Error with cache notification.

– Adapter engine not found.

– Business system not found on execution of LCR_GET_OWN_BUSINESS_SYSTEM.
We had to do the following steps in the below order to get it working:
- Recreate SAP technical systems
a) Delete existing technical systems for SAP systems.
b) Regenerate these technical systems (RZ70).
2.Regenerate PI business system and technical systems of type “Process Integration”
a)Delete all technical systems of type ‘Process Integration’.
b) Delete PI business system
c) Execute PI self registration:
In SAP Net Weaver Administrator:
Configuration Management –> Scenarios –> Configuration Wizard : All Configuration Tasks –> PI SLD Self Registration
This step:
i) Regenerates technical systems of type ‘Process Integration’
ii) Recreates PI business system. If PI business system is not deleted in 2 b), this step will fail. If you want to use a different name, it should be done after all steps are complete.
3.Restart integration builder / integration repository / RWB and AE.
Net weaver Administrator:
SAP Netweaver Administrator –> Operation
Management –> Systems –> Start&Stop –> Java EE Applications
- com.sap.aii.af.app (Adapter Engine)
- com.sap.xi.directory (Integration Builder/Configuration)
- com.sap.xi.repository (Integration Builder/Design)
- com.sap.xi.rwb (Runtime Workbench)
4.Adjust all SAP business systems to use the new technical system. The technical systems should appear as below.

Hopefully it can save someone some time in trying to work these out.
